后端应用服务宕机常见原因分析与解决方案分享
文章导读
对于国内的应用投产服务生态环境而言,大多指的都是JAVA的生态环境。本文也是基于Java,用于记录JVM在运行中宕机的几种常见故障,并辅以shell语言提供了相关的解决和排查方案。文中不会太过于向你分析jvm的内存模型原理,而是以实战的视角向你分析宕机故障可能存在的原因,以及发生此类故障时的现象和与之对应的解决思路。如果你的故障和我关于所描述的现象的呼应上了,那么你可以使用我所提供的方案来尝试解决你的问题。
由内存导致的宕机
对于JVM的内存宕机故障而言,你所看到的教程一般会为你先分析内存模型中关于堆空间中新生代,老年代,元空间等的相关概念。其实在实际的实战经验中关于内存导致的宕机你只需要关注两个指标即可,一是老年代当前占比,一是FULL GC执行情况。因此我也将通过这两个指标带你进行内存故障分析实战。
当系统发生内存故障时,在应用日志中记录的关键日志就是:Out Of Memory(内存不足)。面对这个信息,你需要明白两个概念:
通过上面对于内存溢出或者是内存泄露的概念解释,你应该要注意到一个很重要的特性,及一次性与持续性的区别,通过这个区别我们来对故障现象进行说明:
在内存泄露的情况下,应用程序的宕机在老年代,和full gc指标上会有这样的几个特征:1、老年代所占比例一般会在80%以上(更多的是在90%以上)2、对full gc回收信息查看的时候会发现full gc的次数在1分钟以内至少执行了1次以上。而这两个指标在应用系统上的表现就是系统长时间无响应,但是存在你锲而不舍的刷新时有可能给你响应一次返回数库。
内存泄露的指向一般也是指向于代码。而代码中的业务场景常见的有:
执行定时任务,且定时任务频率比较高。当每个时间段需要执行的任务多,每个任务单独一个线程执行时
#full gc执行信息查看,其中1000为输出间隔,单位毫秒。 jstat -gcutil pid 1000
在内存溢出的情况下,你会在应用日志中看到Out Of Memory(内存不足)的信息,但是当你查看full gc指标信息的时候,一般不会出现上面内存泄露中提到的现象,full gc的指标信息看起来应该是会很正常,有的只是应用服务无法响应。对于内存溢出而言往往与这些业务行为存在关联1、数据库返回大量数据到后端。2、后端一次性加载大量文件内容做逻辑处理。3、上传或者下载文件加载内容到内存做逻辑处理。当然在业务行为判断之外,你可以通过反证法来判断。因为内存溢出与内存泄露都归属于堆内存,因此你可以判断如果full gc指标现象不同于内存泄露的你可以直接归为内存溢出。
面对Out Of Memory(内存不足)以及导致问题的两个概念时,从上面的分析中我们只能分析出该故障属于那个概念,但是更加底层的原因并没有分析出来。例如:是那段代码存在内存泄露,是什么业务行为导致了内存溢出。对此我们一般是通过dump内存文件进行分析。
#dump内存快照 jmap -dump:[live,]format=b,file= #示例 jmap -dump:live,format=b,file=/tmp/dump.hprof 16
对于生成的内存快照,一般是建议拉到windows平台上通过jdk提供的jvisualvm.exe进行查看。可能很多的人对于使用这个没有经验,即使打开了堆内存文件也不知道怎么查看有用的信息。这里可以给大家分享一个实战中的经验。
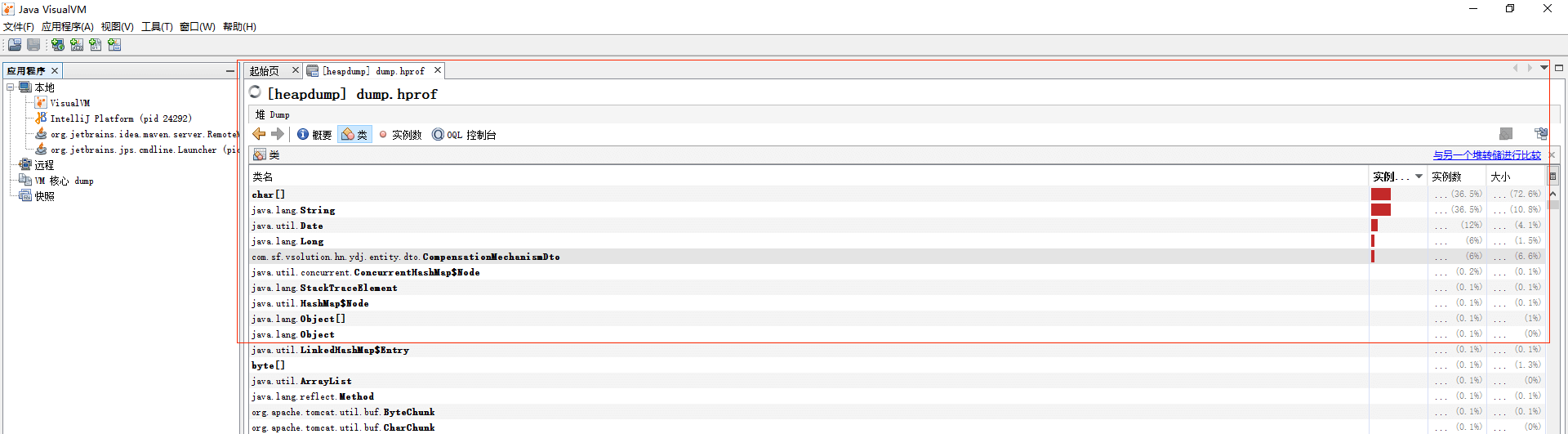
由连接数导致的宕机
对于JVM由连接数导致的宕机故障而言,你需要关注一个很重要的指标:即TOMCAT默认连接数和队列长度。一般而言我们很少会去主动配置tomcat的连接数,因此默认连接数为:200,队列长度为:100,当队列长度都占满的时候,请求会返回connection refused,而处于队列种的请求则会表现出无响应的状态。当然在你的内存与CPU资源充足的情况下,你可以提高数值,毕竟资源不用白不用。所以对于连接数导致的宕机,你可以通过netstat命令来检查tomcat的当前连接数。
netstat -anp | grep java | wc -l
在以往的实际经验中,发生这个故障主要有以下几种情况:
1、假设你的服务器在国内而要访问的地址在国外,突然因为网络故障,导致请求缓慢或者超时。导致服务器已经断开了你的连接,而你却没有设置请求的超时时间。这是通过netstat命令,你的tcp/ip状态是处于close_wait状态。然后持续性的请求导致了连接数积压,导致宕机。
2、和你对接系统,你推送数据给他。它的返回响应变得缓慢。而你需要等待它响应完成才会主动断开连接。进而导致链接积压引起链接数导致宕机。
因此,此类宕机一般要满足两个条件:1、业务处理时间变长;2、连接超时时间配置过长。可能你会说,处理时间够快,但是海量连接过来也会导致服务无法响应,其实这种情况。不能问题是连接数导致了宕机,你也很难去通过修改代码的超时时间解决,而是应该在服务器资源允许的条件下加大连接数或者是直接对应用做横向扩展。
由CPU导致的宕机
对于CPU导致的宕机故障而言,普遍伴随着CPU升高的情况。cpu升高的情况主要是以下几种:1、代码陷入死循环。2、未使用到线程池无限创建线程(该情况也可能导致内存泄露)。3、线程死锁,导致后续线程锁等待而积压。
而上面三种情况伴随的业务场景由如下几种:
1、由定时任务导致的情况。及单位时间段内需要执行的任务数量多,单个任务执行时间长且没有使用线程池。当下一轮任务开始时,上一轮的任务还没有执行完,导致了线程的叠加。这种情况会导致cpu占用逐渐升高,以及内存泄露的情况发生。至于是CPU还是内存先导致宕机,取决于他们的资源谁先耗尽。
对于线程故障,不可避免的是dump线程信息对其进行分析。不过在实际的运维领域这并不是一个第一的选择方案,主要是因为执行起来耗时长。因为CPU的故障往往都是伴随CPU升高,所以我们可以通过查询那个线程占用CPU高来反推。具体的执行手段不应该是手动执行》通过进程找线程》通过线程ID转16为进制》在通过16进制打印线程信息。
而是应该使用show—buys-java-threads.sh自动化脚本或者是使用arths工具来排查。因为线上故障处理突出的就是要快、准。
jstack -l pid > jstack.log
关于宕机故障的常用解决方案
知识引申
https://juejin.cn/post/6958432888723341342
本文系作者 @Mr.Lee 原创发布在 维简网。未经许可,禁止转载。